Free Crawlability Checker
Instantly Test Your Website’s Search Engine Accessibility
Test if Google can find and access your website pages. Click Raven’s free tool checks your robots.txt file and crawl permissions, helping you fix issues that could hurt your search rankings.
How it works
Enter your website URL
Type your website URL in the input field above. You can check any page on your site, from the homepage to specific articles or product pages.
Instant Results generated
Get a detailed report showing crawl rules, robots.txt directives, and accessibility status. Our analysis shows what Google’s mobile crawler sees when visiting your site.
Use your free report to Optimize Your Site
Use the insights to fix crawlability issues, update robots.txt files, and ensure search engines can properly discover your content.
Why use Click Raven’s Crawlability Checker?
✔ It’s Free. No Signup Required– Instantly check your website’s search engine accessibility without creating an account or paying fees.
✔ User-Friendly Interface– Designed for ease, our tool offers a straightforward process for testing website crawlability.
✔ Real-Time Crawlability Analysis– Get precise, real-time insights into your site’s accessibility to search engine crawlers and robots.txt configuration.
✔ Detailed Robots.txt Examination- See exactly what your robots.txt file tells search engines, including allow and disallow rules.


More than just a Crawlability checker
Click Raven offers a powerful suite of free SEO tools to help you optimize for search engines and improve website visibility. Check out these additional tools:
✔ Keyword Density Checker– Find out how often your target keyword appears in your content compared to your total word count.
✔ Keyword Research Tool– Discover new keywords to boost your search visibility and content relevance, completely free.
✔ Meta Tags Extractor– Extract meta tags from any website’s HTML code to analyze how search engines read page titles and descriptions.
✔ Bing Rank Checker– Instantly check your website’s ranking positions on Bing search engine for any keyword.
✔ Bad Links Checker– Identify and fix broken internal or external links that may hurt your search rankings.
The Ultimate Guide to Website Crawlability in 2025
Can’t get your website to show up in Google search results? The problem might be crawlability. If Google’s crawlers can’t access your pages, your content won’t rank, no matter how good it is.
This happens more often than you’d think. Many website owners invest heavily in keyword research and content creation, only to discover that technical barriers prevent search engines from finding their pages.
Crawlability is how Googlebot, Google’s primary web crawler, discovers, accesses, and processes the content on your website. A poorly crawled site doesn’t just lose out on organic search rankings. It also risks being entirely omitted from the AI-powered answers that are becoming integral to the user experience.
This guide shows you exactly how to test if Google can access your website, what problems to look for, and how to fix them. We’ll walk you through using our free crawlability checker and explain what the results mean for your search rankings. Dive in!
1. What Is Crawlability?
Before diving into the details, let’s understand what crawlability entails and its precise role in your SEO success.
1.1 Definition & Role in SEO
Crawlability refers to a search engine bot’s ability to access and read the content and code on your website. It is how easily Google’s crawler can navigate from one page to another, understand your site’s structure, and process its content.
The distinction between crawlability and indexability is critical:
- Crawlability: Can Googlebot access this page?
- Indexability: Once accessed, can Googlebot understand and store this page in its index so it can be displayed in search results?
A page must first be crawlable to even have a chance at being indexable. If Googlebot can’t get to a page, it will never be indexed, meaning it will never appear in search results.
This directly impacts your visibility on traditional Google Search and critically on emerging AI tools like SGE and ChatGPT. In addition, these AI models synthesize information primarily from Google’s index.
So, if your content isn’t in that index because of crawl issues, it won’t be considered even for AI-generated summaries or citations.
1.2 How Googlebot Crawls Websites
Think of Googlebot as a tireless librarian with many books (web pages) to read. It doesn’t just stumble upon your site but operates systematically. Also, since Google now uses only mobile crawlers to access all websites, it may not appear in search results if your site isn’t mobile-friendly.
Here’s how Googlebot crawls your website:
Crawl Queue and Crawl Budget
Every website has a place in Google’s crawl queue, a list of URLs the crawler intends to visit. How often and deeply your site gets crawled depends on your crawl budget: the number of pages Googlebot will fetch from your site within a set time.
This crawl budget is influenced by:
- Site size: Larger websites have more URLs to consider.
- Authority and popularity: High-authority sites tend to get crawled more often.
- Content update frequency: Sites with fresh content earn more frequent revisits.
- Server performance: A sluggish or error-prone site may automatically throttle Google’s crawling activity.
How Sitemaps, Links, and Server Signals Affect Crawling:
a. Sitemaps
An XML sitemap gives Google a structured roadmap of your site. While not mandatory, it’s a strong signal that helps Google prioritize which pages to crawl, especially for new or deeply buried pages.
b. Links (Internal & External)
Links are Googlebot’s pathways to discover new pages. Internal links help distribute crawl equity across your site, making it easier for Googlebot to find all relevant pages. External backlinks, on the other hand, act as votes of trust and help Google discover your domain in the first place.
To monitor both types, Click Raven’s Internal and External Links Checker can help surface structural gaps or broken paths.
c. Server Signals
Your web server plays a silent but critical role. They communicate with Googlebot through HTTP status codes to tell Googlebot whether a page is accessible:
200 OKmeans proceed404 Not Foundor500 Server Errorcan discourage future crawls
A consistently fast server response and healthy status codes signal to Google that your site is reliable and worth crawling frequently. Conversely, slow response times or frequent errors will tell Googlebot to reduce its crawl rate.
2. Common Crawlability Issues
Even well-structured websites can get crawlability issues that silently sabotage their SEO efforts. Therefore, identifying and rectifying these is important.
Here are the common crawlability issues and how to fix them before they chip away at your organic visibility:
2.1 Broken Internal Links
A broken internal link, whether it points to a 404 page or redirects in a loop, is a dead end for Googlebot.
When Google’s crawler hits one of these, it doesn’t keep guessing. It stops trying to follow that path, potentially leaving valuable pages undiscovered or indicating a poorly maintained site.
How to detect and fix them
Use Google Search Console’s “Crawl Errors” report or run a full audit with tools like Screaming Frog, Ahrefs Site Audit, or Sitebulb to flag broken URLs. Once identified:
- Update links to the correct URL
- Remove links pointing to deleted pages
- Set up clean 301 redirects where appropriate
2.2 Orphan Pages
Orphan pages are live URLs on your server that are not linked to any other page within your website’s internal structure.
Since Googlebot heavily relies on the internal linking structure to crawl and prioritize content, if a page has no internal links, it might never find it, even if it’s included in your sitemap.
Why are sitemaps not enough?
While a sitemap lists all pages, Google often prioritizes pages discovered through internal links, which signal importance and context. An orphaned page, even in a sitemap, might be crawled less frequently or deemed less necessary by Google.
2.3 Blocked by Robots.txt or Meta Tags
These are often accidental but critical errors.
a. Disallow and noindex issues
- Robots.txt: This file tells crawlers which parts of your site not to visit. A
Disallow: /rule effectively blocks your entire site. Often, staging sites accidentally carry this rule over to live environments. MisconfiguredDisallowrules can prevent Google from accessing important CSS/JS files, leading to rendering issues. - Meta Robots Tag (
<meta name="robots" content="noindex, nofollow">): This HTML tag tells crawlers not to index a page (remove it from search results) and/or not to follow links on that page. Accidentally applyingnoindexto crucial pages is a common and devastating crawlability/indexability error.
b. Accidental blocks (e.g., staging, tag pages)
It’s common for developers to block staging environments from crawling. Without removing this rule before going live, your entire site will be invisible.
Similarly, default CMS settings might noindex or disallow low-value pages like tag archives, author pages, or filtered search results, which is often intentional, but sometimes valuable content gets caught in the crossfire.
Regularly check:
- Your
robots.txtfile using Click Raven’s Robots.txt Checker or Search Console’s robots.txt tester - Your
<meta robots>settings on high-priority pages
And audit these settings during site migrations, CMS changes, or redesigns.
2.4 Slow Server Response or 5xx Errors
Crawlability is directly tied to server health and depends on speed and uptime. If your server is consistently slow to respond (high Time To First Byte – TTFB) or frequently returns 5xx (server error) status codes, Googlebot will get frustrated.
How server issues hurt crawl depth
Google aims for efficiency. If crawling your site becomes resource-intensive or unreliable due to server performance, Google will reduce your crawl budget, visiting fewer pages and less frequently. This means new content takes longer to be discovered, and updates to existing content aren’t registered promptly.
3. How to Check if Your Site Is Crawlable
Now that we understand the common pitfalls, let’s look at the best tools to diagnose your site’s crawlability.
3.1 Use Google Search Console (GSC)
GSC is your direct line of communication with Google and the most authoritative source for crawlability information. Here are the two features in GSC you’ll want to pay the most attention to:
a. Coverage Report
This is your primary diagnostic tool for understanding how Google interacts with your site. It helps you see what’s
- Indexed: Google has successfully crawled and added these pages to its search index.
- Errors: These show critical issues like server errors, redirect loops, or URLs blocked by your robots.txt file.
- Excluded: Pages in this category weren’t indexed, and GSC explains why. Common reasons include:
- Blocked by robots.txt
- Marked with a “noindex” tag
- Crawl anomalies (Google tried but couldn’t finish)
- Discovered but not yet crawled
Use this report to spot patterns and zero in on what’s holding back your visibility.
b. URL Inspection Tool
Need to troubleshoot a specific page? This tool shows you how Google sees it.
You can check if the URL is indexed, if there are any indexing errors, and even “Request Indexing” or “Test Live URL” to see if Google can crawl and render the page successfully.
This is especially helpful for new or updated content that Google hasn’t yet picked up.
3.2 Use the Click Raven’s Crawlability Checker
This is the most straightforward way to test crawlability since it’s free and requires no login or signup. It is also the best solution for a quick, comprehensive, and user-friendly audit.
A dedicated Crawlability Checker tool like ours can be necessary, especially for non-technical marketers and site owners who need a clear, actionable overview without diving deep into complex logs or code. Here’s why:
This tool automatically detects:
- Orphaned Pages: By comparing pages found via internal links with those in your sitemap, it flags pages that are not discoverable through your site’s navigation.
- Blocked URLs: It identifies pages explicitly disallowed by robots.txt or containing
noindexmeta tags. - Sitemap Coverage: It cross-references your sitemap with actual crawled pages to ensure all intended URLs are being discovered.
- Crawl Delays: While not a direct measure of Google’s crawl budget, it can highlight slow-loading pages or sections that might deter efficient crawling.
- Broken Links: Instantly flags internal links that lead to 404s or other errors.
Here’s a step-by-step guide on how to use it:
Step 1: Submit your website URL
Enter your website URL in the tool above and click “Submit.”

Step 2: Generate Crawlability Results
Our tool will scan your website and analyze your robots.txt file, examining crawl permissions and accessibility status. You’ll receive detailed insights similar to what search engines see when they visit your site.
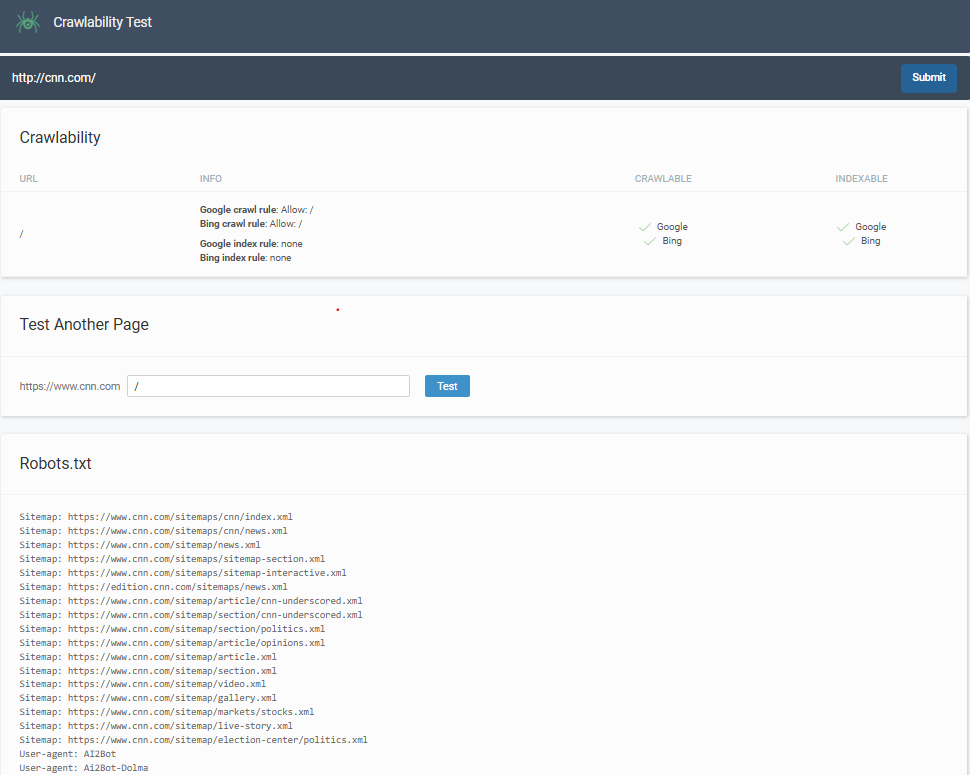
Step 3: Use your free report to optimize Your Site
Use the insights to fix crawlability issues, update robots.txt files, and ensure search engines can properly discover your content.
3.3 Other Tools (Secondary Mentions)
For more advanced or specific audits, these tools are invaluable:
- Screaming Frog SEO Spider: A powerful desktop-based crawler that emulates Googlebot. It crawls your site, identifying broken links, redirects, missing meta tags, robots.txt issues, and more. Essential for in-depth technical audits.
- Ahrefs Site Audit / Semrush Site Audit: Integrated within larger SEO suites, these cloud-based crawlers provide comprehensive site audits, including detailed crawlability and technical SEO reports, often with prioritization based on severity.
- Sitebulb: Another robust desktop crawler known for its excellent visualizations and actionable recommendations, making complex crawl data easier to interpret.
4. How to Fix Crawlability Issues
Identifying issues is the first step; fixing them efficiently is the next.
4.1 Update Internal Links
This is the most fundamental fix for orphaned pages and crucial for crawl depth.
- Link orphaned pages: If Googlebot can’t find a path to a page through internal links, chances are it won’t crawl, no matter how great the content is. Use internal links naturally within your main content and consider secondary placements in headers, footers, or breadcrumb navigation.
- Use contextual links: Embed links where they make sense within content. For example, linking product pages within blog posts or vice versa strengthens topical relevance and distributes authority.
- Fix broken links (404s): Prioritize fixing 404 errors flagged in Google Search Console or any site audit tool. Either update the link to the correct destination or redirect it to a live, relevant page.
4.2 Repair Robots.txt and Meta Tags
Careful auditing is key here to avoid accidental blocks.
Audit Disallow Rules and Noindex Use
Review your robots.txt file and your site’s code for any noindex meta tags.
- Examples of safe vs. risky blocks:
- Safe: Disallowing
wp-admin(WordPress backend) oradmin/directories. Noindexing internal search result pages, filtered e-commerce product listings (e.g.,?color=red&size=small), or login pages. - Risky: Disallowing entire
wp-contentorassetsfolders (which contain CSS/JS, preventing Google from rendering your page correctly). Noindexing entire categories of products or blog posts that should be indexed.
- Safe: Disallowing
Test Changes
After modifying robots.txt, use GSC’s robots.txt Tester to ensure your changes have the desired effect before uploading. For noindex tags, use the URL Inspection Tool to verify.
4.3 Improve Sitemap Structure
A well-structured sitemap is only helpful if it’s accurate and manageable.
- Split Large Sitemaps: For very large sites (over 50,000 URLs), split your sitemap by content type, e.g.,
/sitemap-products.xml,/sitemap-blogs.xmland reference them in a single sitemap index file. This makes it easier for Google to process them. - Include Only Indexable URLs: Your sitemap should only contain URLs you want Google to index. Do not include noindex pages, broken links, or pages blocked by robots.txt.
- Update it regularly: Outdated sitemaps can mislead Google about the structure and relevance of your site.
4.4 Reduce Crawl Wastage
Help Googlebot focus its limited crawl budget on your most valuable content.
- Block Tag Archives, Filtered URLs, Pagination Where Needed: Often, parameters in URLs (
?sort=price,?page=2), duplicate content from tag archives, or highly similar pagination pages can consume crawl budget without adding SEO value.- Use
noindex, followsmartly: For pages you don’t want in the index but want Google to follow links from (e.g., paginated archives where you still want links on page 2 to be followed), usenoindex, follow. - Use
rel="canonical": For duplicate content (e.g., product variations or syndicated content), use therel="canonical"tag to point Google to the preferred, indexable version. - Parameter Handling in GSC: You can tell Google Search Console how to handle specific URL parameters to avoid crawling duplicate content.
- Use
5. Crawlability and AI Search (SGE & Chatbots)
The rise of AI in search has not diminished the importance of crawlability but amplified it.
5.1 Why Crawlability Still Matters in the Age of AI
Google’s AI Overviews, which power SGE, are built directly upon Google’s core index.
That means if your site isn’t being crawled, it’s not being indexed, and if it’s not indexed, it’s not showing up in AI summaries, no matter how good your content is.
AI can’t cite what it can’t crawl
AI models need well-structured, accessible, and understandable data to draw from. A messy, uncrawlable website presents a significant barrier to these models, making your content effectively invisible to the AI layer of search.
5.2 LLM Citations Depend on Clean Crawled Content
The goal is not just to be crawled, but to be crawled cleanly.
a. Messy URLs = Ignored by AI
If your URLs are filled with tracking parameters, session IDs, or are otherwise inconsistent, it is harder for Google’s crawlers (and thus, AI models) to identify and prioritize the core content. This can lead to your content being overlooked for citations within AI summaries.
b. Strong Structure + Internal Linking = Higher Visibility in LLM Outputs
Just as a well-structured site with clear internal linking signals authority and relevance to traditional Googlebot, it also signals the same to AI models.
Content that is easy to crawl, well-organized, and internally linked comprehensively within a topic cluster is more likely to be understood, synthesized, and cited by LLMs, giving you a competitive edge in the evolving search landscape.
Conclusion: Don’t Let Crawl Issues Kill Your Visibility
In an SEO ecosystem that never sits still, crawlability remains non-negotiable. It’s how Google discovers you, understands you, and decides whether you’re worth showing in an AI-powered search experience.
You can write the best content in your category. You can optimize every meta tag. But if bots can’t reach or process your pages, none matters. You’re invisible.
Crawl optimization shouldn’t be a once-a-year cleanup. It should be baked into your SEO hygiene. Regularly.
Start with something simple but effective, like Click Raven’s Crawlability Checker, which flags broken links, blocked pages, and indexing issues that silently sabotage your rankings.
The bottom line? If Googlebot can’t get through your site, neither can your audience.